This project consists of the development of an information retrieval system and data analysis of the news published on the front page of the "Jornal Público" in the domain http://www.publico.pt/ over the period of time between 2010 and 2021.
For the realization of this project we used the news preserved by Arquivo.pt. In total, 10,976 versions of the main page of Jornal Público were collected, from which a total of 67,242 news items were extracted.
Project Objectives
The main objectives of this project are to provide an information search system that allows users to carry out searches on any subject that has been the subject of news coverage by "Jornal Público" in the publico.pt domain, between 2010 and 2021. Additionally, we provide to Arquivo Público users an analysis of the data obtained focusing on the relevant words, locations, organizations and people mentioned in the set of 67,242 articles collected. We also offer users a similar data analysis, restricted to the set of news related to the Covid-19 pandemic. The architecture developed within the scope of this project may be (in the future) adapted to other media.
Arquivo Público Architecture
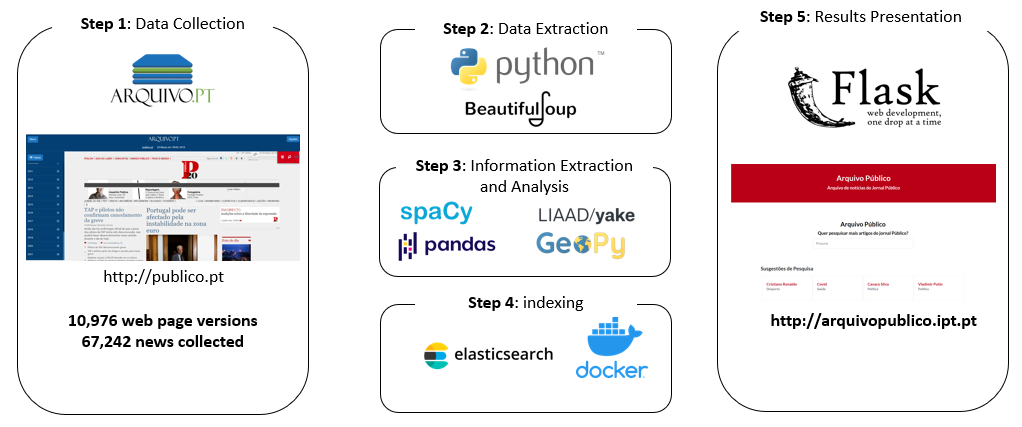
To carry out this project, we used the TextSearch API of Arquivo.pt to obtain a total of 10,976 versions of the main page of Público newspaper in the period between 2010 and 2021. Subsequently, we use web scrapping techniques to automate the process of extracting information, namely the title, description, date, link and author of each one of the news. The change in the graphic look on the main page of the "Jornal Publico" that took place in 2012 and 2017 forced an adaptation of the webscraping process by our team in each of those years. Additionally, we extract information from the news collected using spacy (automatic detection of entities), yake (automatic extraction of relevant words) and geopy (mapping of locations identified by spacy in geodetic coordinates). For indexing the information collected and implementing the search system, we used Elastic Search. Finally, we proceed to the development and availability of the website using Flask technology. The architecture described here is based on Docker and is adaptable to different scenarios and social media.
The figure below illustrates the architecture of our system.
Presentation to the Jury of the Arquivo.pt Award 2022